이번 포스트에서는 빅 데이터 분산 처리∙분석 오픈소스 데이터 관리 플랫폼중 하나인 Hadoop에 대해 알아보도록 하겠습니다.
1. 분산 파일 시스템 (Distriuted File System)
DFS (Distributed File System)는 클라이언트가 자신의 컴퓨터에 있는 것처럼 서버에 저장된 데이터에 액세스하고 처리 할 수 있는 클라이언트 / 서버 기반의 응용 프로그램입니다. 사용자가 서버의 파일에 접근하면 서버는 사용자에게 파일의 복사본을 전송합니다. 이 복사본은 데이터가 처리되는 동안 사용자의 컴퓨터에 캐시 된 후 서버로 반환됩니다.
분산 파일 시스템은 Master / Slave 구조로 되어 있는데 대략적인 구조는 아래 그림과 같습니다.

분산 파일 시스템은 NameNode, Secondary Name Node, Data Node로 크게 구성되어 있습니다.
Data Node는 Slave로써 실제 데이터를 저장하고 있는 부분이며 Name Node과 Secondary Node는 Data Node들에 대한 Meta Data 정보를 가지고 있는 Master입니다.
Data Node와 Name Node는 연결되어 있지만 서로 통신을 하는 구조가 아니며 Data Node가 주기적으로 Heart Beat이라는 상태 정보를 Name Node로 보내게 됩니다. Name Node는 이러한 정보들을 바탕으로 Data Node들의 상태를 파악하고 어느 Data Node에 데이터를 저장할 지 정하게 됩니다.
분산 파일 시스템은 하나의 파일을 분산해서 저장하기 때문에 같은 파일을 여러 곳에 복제하여 저장합니다. Hadoop의 경우 하나의 파일을 3개의 파일로 만들어 3군데에 저장하게 됩니다. 3군데에 저장하게 된다면 어떠한 일이 있더라도 데이터가 유실되지 않는다는 것이 수학적으로 증명이 되었기 때문입니다.
그럼 데이터를 어떻게 가져올까요?
클라이언트는 Name Node로 명령어를 전송하게 됩니다. Name Node는 메타 데이터를 바탕으로 사용자가 요청한 파일이 있는 Data Node 중 하나를 선택하여 클라이언트에게 알려줍니다. 그 후 클라이언트는 해당 Data Node로 직접 접근하여 파일을 읽게 됩니다. 중요한 것은 Name Node를 통해서 데이터 노드로 접근하는 것이 아닌 클라이언트가 직접 데이터 노드로 접근을 한다는 것입니다. 이렇게 하는 이유는 여러 클라이언트가 동시에 많은 요청을 했을 때 네임 노드를 통해 접근하게 되면 네임 노드에 엄청난 부하가 걸리게 되어 서버가 죽을 수 있기 때문입니다.
2. Hadoop
Hadoop은 Yahoo! 개발자였던 더그 커팅이 구글의 데이터 관리 체계인 GFS(Google File System)와 MapReduce의 논문을 바탕으로 2006년 개발한 빅데이터 분산 처리 / 분석 오픈소스 데이터 관리 플랫폼입니다. Java 기반이며 JVM위에서 동작하게 됩니다. Hadoop은 HDFS(Hadoop Distributed File System)에 대용량 빅데이터를 분산 저장하고, 분산 처리를 위해 MapReduce를 이용해 대용량의 빅 데이터를 처리하게 됩니다.
Hadoop Cluster는 네트워크로 연결되어 있는 범용 컴퓨터들의 집합체를 말합니다. 네임 노드, 데이터 노드가 묶인 것을 하나의 Hadoop Cluster라고 하며 이 Cluster들은 여러 개가 존재합니다. 규모에 따라 수천개가 존재할 수도 있고 이는 설계를 어떻게 하느냐에 따라 달라집니다.

위 그림은 Hadoop 시스템이 데이터를 저장하는 방식입니다. 데이터 블록을 3개의 블록으로 복제한 후 각각 다른 곳에 저장합니다. 각각 다른 곳이라는 것의 정의는 물리적으로 독립적인 위치에 저장된 다른 곳입니다. 예를 들어, 같은 건물 내 다른 곳(강의실 101, 강의실 201)이라고 한다면 건물 전체가 정전이 된다면 모든 강의실에 있는 데이터 노드들이 죽게 될 것입니다. 이는 물리적으로 독립되어 있다고 하지 않습니다. 분산 저장의 목적이 Fault Tolerance에 있기 때문에 다른 건물, 다른 지역에 저장이 되어야 하는 것이 중요합니다.
3. Hadoop 1.X Architecture

1) Name Node
Hadoop은 Master/Slave 구조를 가진다. NameNode는 HDFS에서 마스터 역할을 하며, 슬레이브 역할을 하는 DataNode에게 I/O 작업을 할당합니다.
2) Secondary NameNode
HDFS의 블록이 변경되더라도 실시간으로 변경정보를 갱신하지는 않습니다.
Secondary NameNode는 주기적으로 NameNode의 파일 시스템 이미지 파일을 갱신하는 역할을 하며, 이러한 작업을 체크포인트라고 합니다. Secondary NameNode는 NameNode의 백업 노드가 아니라는 것이 중요합니다. 데이터를 통으로 저장하는 것이 아닌 이미지 파일을 갱신하는 것으로 이해하시면 됩니다.
3) Data Node
실제 데이터는 DataNode에 저장됩니다. Client가 HDFS에 파일을 읽거나 쓰기 위해 NameNode에게 요청을 보내면, NameNode는 어느 DataNode의 어디 블록에 파일이 있는지 Client에게 알려줍니다. 그러면 클라이언트는 DataNode와 직접 통신하여, 파일을 읽거나 쓰게됩니다. 즉 DataNode와 블록 위치가 정해지면 Client는 NameNode와는 전혀 통신하지 않고, 해당 DataNode와 직접 통신을 하게 됩니다.
DataNode는 주기적으로 NameNode에게 하트비트(heartbeat)와 블록의 목록이 저장된 블록 리포트(blockreport)를 전송합니다. 또한 자신의 Local Storage에 변경 사항이 발생할 때마다 Name Node에게 변경 사항을 알려줍니다.
4) Job Tracker
JobTracker는 Task 할당과 모니터링을 하는데 만약 어느 DataNode에서 태 스크가 실패하면 Task를 다른 DataNode에 재할당하고 재실행하도록 명령합니다. 일반적으로 JobTracker는 마스터 노드, 즉 NameNode에서 실행됩니다.
5) TaskTracker
Task 수행은 DataNode에 존재하는 TaskTracker가 담당합니다. DataNode에는 하나의 TaskTracker만이 존재하게 되며 얼 개의 JVM을 생성해서 다수의 Map과 Redece 연산을 수행하게 됩니다.
4. Hadoop 2.X Architecture
Hadoop 1.0에서의 Job Tracker는 클러스터 전체의 리소스를 관리하며 여러 잡(Job)을 수행하면서 그것들이 성공적으로 끝날 때까지 관리합니다. 이러한 기능을 Hadoop 2.0 YARN(Yet Another Resource Negotiator)에서는 Resource Manager, Application Master 두 개로 분리되었으며, 이로 인해 다양한 분산처리 환경 지원이 가능해졌습니다.

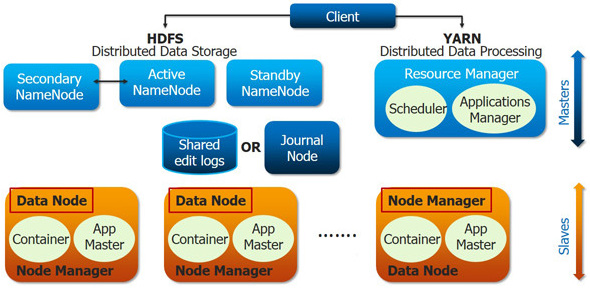
Hadoop 1.0에서는 JobTracker가 클러스터의 자원 배분과 Job관리를 함께 수행 했기 때문에 JobTracker 자체적으로 병목현상이 발생할 수 있습니다. Hadoop 2.0에서는 JobTracker가 하던 두 가지 역할을 Resource Manager와 Application Master로 분리해서 JobTracker에 몰리던 병목 현상을 제거하였습니다. Hadoop 2.0 Cluster Resource Management 플랫폼인 YARN(Yet Another Resource Negotiator)은 Hadoop Cluster의 각 어플리케이션에 리소스를 할당하고, 모니터링하는 업무에 집중함으로써 다양한 어플리케이션이 리소스를 공유할 수 있도록 하는 핵심 요소가 됩니다.
이제 Hadoop 2.0의 구성요소에 대해 살펴보도록 하겠습니다.
1) Resource Manager
클러스터 당 1개 존재하며, 클러스터의 전반적인 자원 관리와 Task들의 스케줄링을 담당합니다. Client로부터 어플리케이션 실행요청을 받으면 그 어플리케이션의 실행을 책임질 Application Master를 실행합니다. 클러스터 내에 설치된 모든 Node Manager와 통신을 통해서 각 Node에 할 당된 자원과 사용중인 자원의 현황을 알 수 있으며, Application Master들과의 통신을 통해 필요한 자원이 무엇인지 알아내어 관리합니다. Resource Manager는 Scheduler와 Application Manager로 구성됩니다.
(1) Scheduler
Node Manager들의 자원 상태를 관리하며 부족한 리소스들을 배정하며, 프로그램 상태를 검사하거나 모니터링 하지는 않습니다. 즉, 순수하게 스케쥴링 작업만 담당합니다.
(2) Application Manager
Node Manager 에서 특정 작업을 위해서 Application Master를 실행하고, Application Master의 상태를 관리합니다. Application Master는 YARN에서 실행되는 하나의 Task를 관리하는 마스터 서버를 지칭하며, 어플리케이션 당 1개가 있습니다.
2) Node Manager
노드 당 한개씩 존재하며, 해당 Container의 리소스 사용량을 모니터링하고, 관련 정보를 Resource Manager에게 알리는 역할을 담당합니다. Node Manager는 Application Master와 Container로 구성되어 있습니다.
3) Application Master
하나의 프로그램에 대한 마스터 역할을 수행하는데 Scheduler로 부터 적절한 Container를 할당 받고, 프로그램 실행 상태를 모니터링하고 관리합니다.
4) Container
CPU, 디스크(Disk), 메모리(Memory) 등과 같은 속성으로 정의되는데 일종의 프로그램같은 것이라고 생각하면 좋습니다. 모든 작업은 결국 여러 개의 Task로 세분화되며, 각 Task는 하나의 Container 안에서 실행되게 됩니다. Container안에서 실행할 수 있는 프로그램은 Java Program뿐만 아니라, Command Line에서 실행할 수 있는 프로그램이라면 모두 가능합니다.

동작 방식을 이해하기 위하여 간단한 예제를 통해 살펴보도록 하겠습니다. 사용자가 넷플리스와 같은 서비스를 통해 'A'라는 영화를 스트리밍으로 보고 싶습니다. 이를 Hadoop 2.X 에서 어떻게 동작하는지 알아보겠습니다.
(1) 클라이언트가 Resource Manager에게 'A'라는 영화를 실행해달라고 요청합니다.
(2) Resource Manager안에 있는 Scheduler는 해당 영화가 있는 Data Node 중 한가한 Data Node에게 Application Master를 생성하라고 요청합니다.
(3) 해당 Data Node의 Node Manager는 Application Master를 생성합니다.
(4) 생성된 Application Master는 ResourceManager 내의 Application Manager에게 자신의 존재감을 알리고 I'm Alive라는 신호(Heart Beat)를 보냅니다.
(5) Application Manager로부터 OK라는 신호를 받게 되면 Application Master는 Node Manager에게 Container를 생성해달라고 요청합니다.
(6) Node Manager는 받은 요청에 따라 Container를 생성합니다.
(7) 스트리밍 형태로 사용자에게 재생 서비스를 제공할 때에는 Container와 사용자가 직접 연결되게 됩니다.
(8) 사용이 종료되면 Application Master는 Resource Manager의 Application Manager에게 자신을 빼달라고 요청하게 됩니다.
조금만 더 살펴보면 Application Master라는 것은 사용자로부터 다양한 제어 권을 부여받게 됩니다. 예를 들면, 재생 버튼, 정지 버튼 등의 제어권을 사용자에게 제공해주는 것입니다. Application Master와 Container는 각각 다른 Thread에서 동작합니다. 따라서 Application Master가 주기적으로 상태를 Application Manager에게 보내는데 보내지 않게 된다면 Alive 상태가 아니라는 판단을 내리고 해당 Application Master를 지우게 됩니다. 마치 컴퓨터가 멈췄는데 아무런 버튼이나 키보드가 먹히지 않는다면 전원을 내리는 것과 같은 것입니다.
Node Manager는 Resource 측면에서 Container를 관리하며, Application Master는 Container의 Status를 관리합니다.
1 Cluster 당 1 Resource Manager
1 Container 당 1 Application Master
1 Data Node당 1 Node Manager
이번 포스트에서는 분산 파일 시스템, Hadoop 1.0, Hadoop 2.0 아키텍처에 대해 알아보았습니다.
최대한 정리해보려고 했는데 아는 내용을 잘 정리하는 것도 어렵네요. 마치겠습니다.
'컴퓨터공학' 카테고리의 다른 글
| 네트워크 보안 - 기본 개념 Summary (0) | 2019.12.19 |
|---|---|
| PySpark - Aggregation and Join (0) | 2019.12.07 |
| 클라우드 컴퓨팅 기술 정리 (1) | 2019.12.03 |
| 클라우드 시스템 개요 (0) | 2019.12.02 |
| 중간고사 정리 (0) | 2019.10.15 |